Calculate seat apportionment for legislative bodies with various methods. These methods include divisor methods (e.g. D’Hondt, Webster or Adams), largest remainder methods and biproportional apportionment.
Mit diesem R-Package können mittels verschiedener Sitzzuteilungsverfahren Wählerstimmen in Abgeordnetensitze umgerechnet werden. Das Package beinhaltet Quoten-, Divisor- und biproportionale Verfahren (Doppelproporz oder “Doppelter Pukelsheim”).
Installation
Install the package from CRAN:
install.packages("proporz")Alternatively, install the development version from Github:
# install.packages("remotes")
remotes::install_github("polettif/proporz")Apportionment methods overview
Proportional Apportionment
proporz() distributes seats proportionally for a vector of votes according to the following methods:
Biproportional Apportionment
Biproportional apportionment (Wikipedia) is a method to proportionally allocate seats among parties and districts. The method is implemented in biproporz().
We can use the provided uri2020 data set to illustrate biproportional apportionment with biproporz(). You need a ‘votes matrix’ as input which shows the number of votes for each party (rows) and district (columns). You also need to define the number of seats per district.
(votes_matrix <- uri2020$votes_matrix)
#> Altdorf Bürglen Erstfeld Schattdorf
#> CVP 11471 2822 2309 4794
#> SPGB 11908 1606 1705 2600
#> FDP 9213 1567 946 2961
#> SVP 7756 2945 1573 3498
(district_seats <- uri2020$seats_vector)
#> Altdorf Bürglen Erstfeld Schattdorf
#> 15 7 6 9
biproporz(votes_matrix, district_seats)
#> Altdorf Bürglen Erstfeld Schattdorf
#> CVP 5 2 2 3
#> SPGB 4 1 2 2
#> FDP 3 1 1 2
#> SVP 3 3 1 2You can use pukelsheim() for dataframes in long format as input data. It is a wrapper for biproporz(). zug2018 shows an election result for the Canton of Zug in a dataframe. We use this data set to create input data for pukelsheim(). The other parameters are set to reflect the actual election system.
# In this data set, parties are called 'lists' and districts 'entities'.
votes_df = unique(zug2018[c("list_id", "entity_id", "list_votes")])
district_seats_df = unique(zug2018[c("entity_id", "election_mandates")])
seats_df = pukelsheim(votes_df,
district_seats_df,
quorum = quorum_any(any_district = 0.05, total = 0.03),
winner_take_one = TRUE)
head(seats_df)
#> list_id entity_id list_votes seats
#> 1 2 1701 8108 2
#> 2 1 1701 2993 0
#> 3 3 1701 19389 3
#> 4 4 1701 14814 2
#> 5 5 1701 4486 1
#> 6 6 1701 15695 3The Apportionment scenarios vignette contains more examples. How to adapt biproporz for special use cases is demonstrated in the Modifying biproporz() vignette.
Shiny app
The package provides a basic Shiny app where you can calculate biproportional apportionment on an interactive dashboard. You need to have the packages shiny and shinyMatrix installed.
# install.packages("shiny")
# install.packages("shinyMatrix")
proporz::run_app()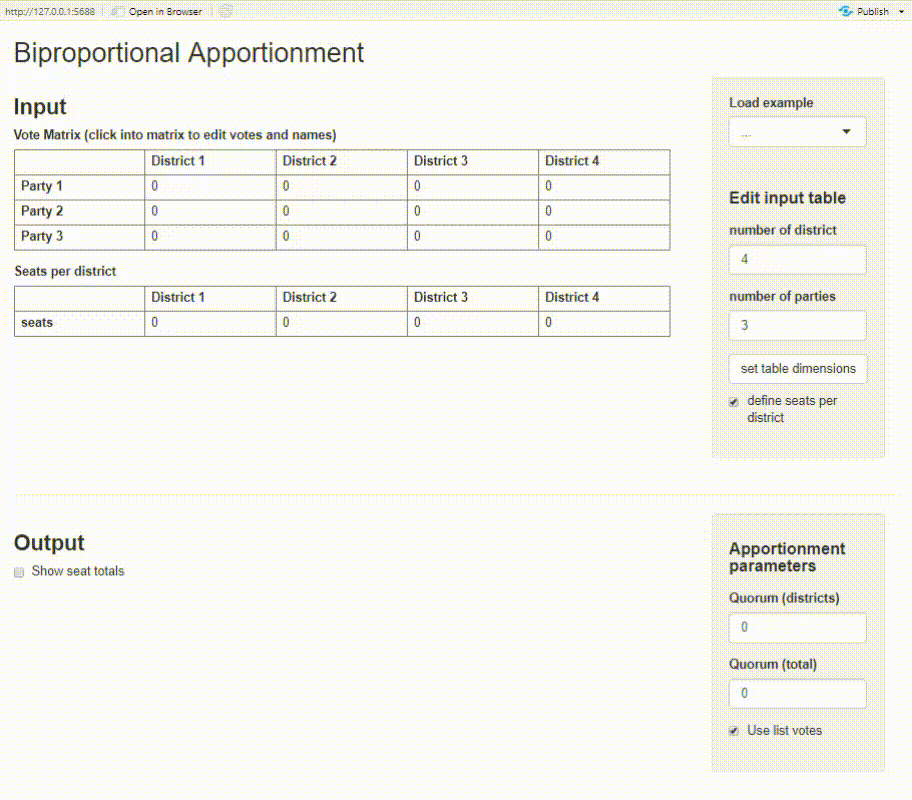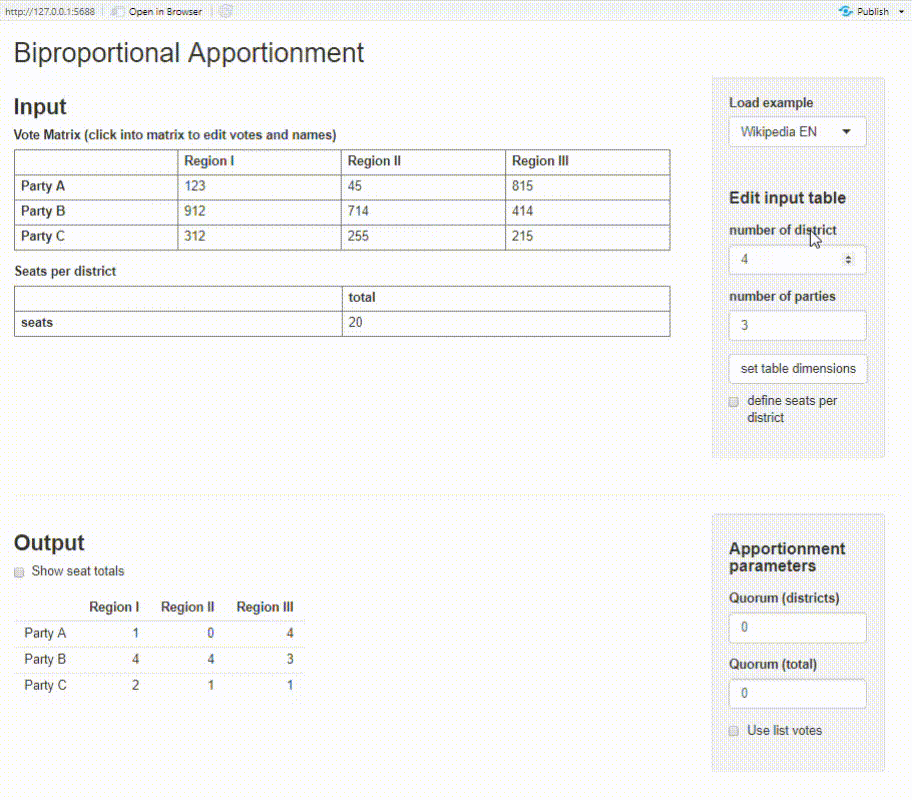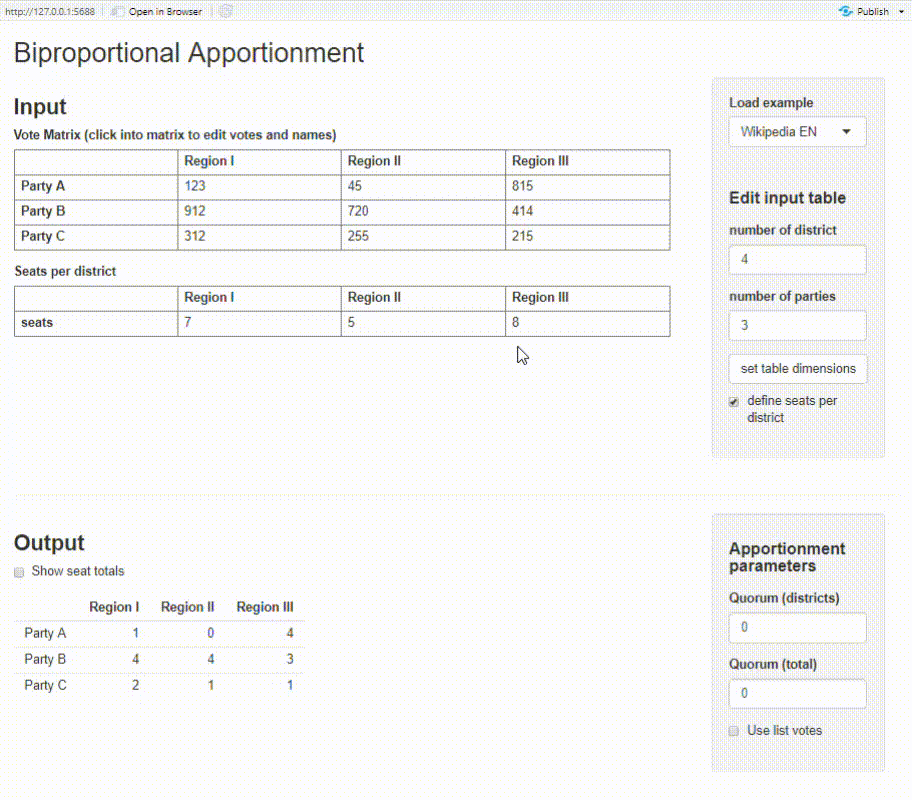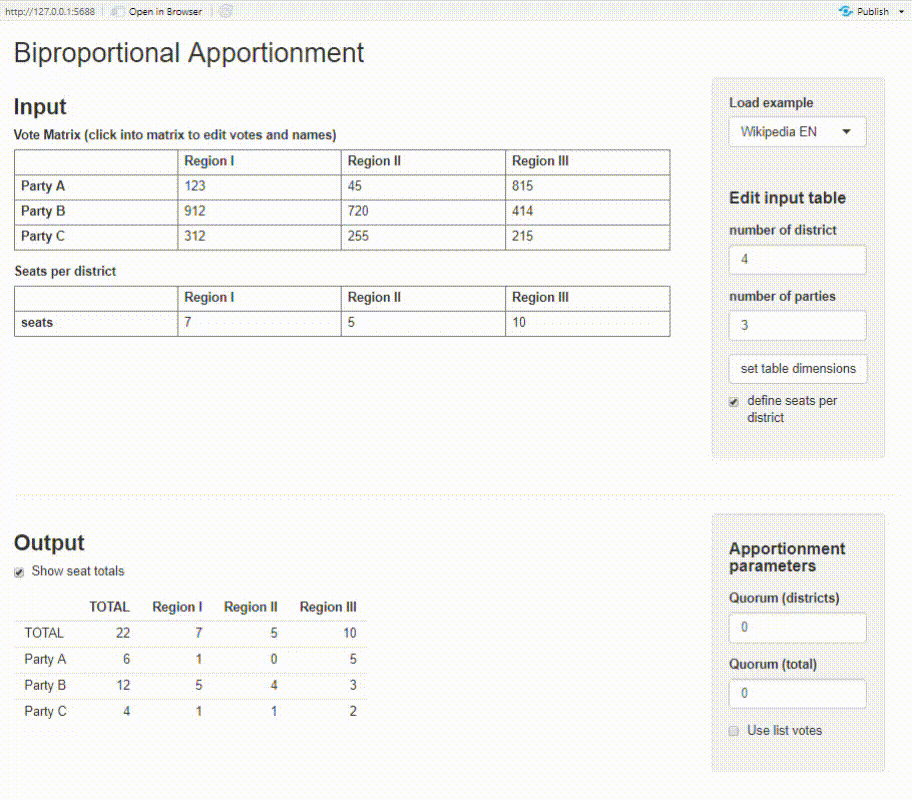
Function details
Divisor methods
You can use divisor methods directly:
votes = c("Party A" = 690, "Party B" = 370, "Party C" = 210, "Party D" = 10)
# D'Hondt, Jefferson or Hagenbach-Bischoff method
divisor_floor(votes, 10)
#> Party A Party B Party C Party D
#> 6 3 1 0
# Sainte-Laguë or Webster method
divisor_round(votes, 10)
#> Party A Party B Party C Party D
#> 5 3 2 0
# Adams method
divisor_ceiling(votes, 10)
#> Party A Party B Party C Party D
#> 4 3 2 1
# Dean method
divisor_harmonic(votes, 10)
#> Party A Party B Party C Party D
#> 5 2 2 1
# Huntington-Hill method
divisor_geometric(votes, 10)
#> Party A Party B Party C Party D
#> 5 3 1 1Largest remainder method
The largest remainder method is also accessible directly:
votes = c("I" = 16200, "II" = 47000, "III" = 12700)
# Hamilton, Hare-Niemeyer or Vinton method
largest_remainder_method(votes, 20)
#> I II III
#> 4 13 3See also
There are other R packages available that provide apportionment functions, some with more focus on analysis. However, biproportional apportionment is missing from the pure R packages and RBazi needs rJava with an accompanying jar.
- RBazi: Package using rJava to access the functions of BAZI.
- seatdist: Package for seat apportionment and disproportionality measurement.
- disprr: Simulate election results and examine disproportionality of apportionment methods.
- apportR: Package containing various apportionment methods, with particular relevance for the problem of apportioning seats in the House of Representatives.
- apportion: Convert populations into integer number of seats for legislative bodies, focusing on the United States.
Contributing
Please feel free to issue a pull request or open an issue.